
Key takeaways
- There’s a misdiagnosed problem in disruption management. A key driver of disruption costs is decision latency. This is the gap between when a problem is knowable and when the network acts on it.
- Local optimization can conflict with network value. Individually rational decisions by gate agents, crew schedulers, and ground handlers can cascade into system-wide failures.
- Visibility is not enough. Better dashboards leave the underlying decision-making structure intact. A step-change reduction of disruption costs requires replacing siloed optimization with real-time, network-wide coordination.
- Manage the decision window, not just the delay. How long the network took to act after disruption began is the metric that matters.
Disruptions are often treated as an operational tax. They are managed, budgeted for, and ultimately absorbed into a cost structure that assumes a certain percentage of flights will never run on time. But we don’t need to accept this as it is. Most disruption costs emerge because of a system that doesn't allow decisions to be made collectively by stakeholders across operations. But for the first time, we have a technology capable of redesigning this system.
The clock nobody is watching
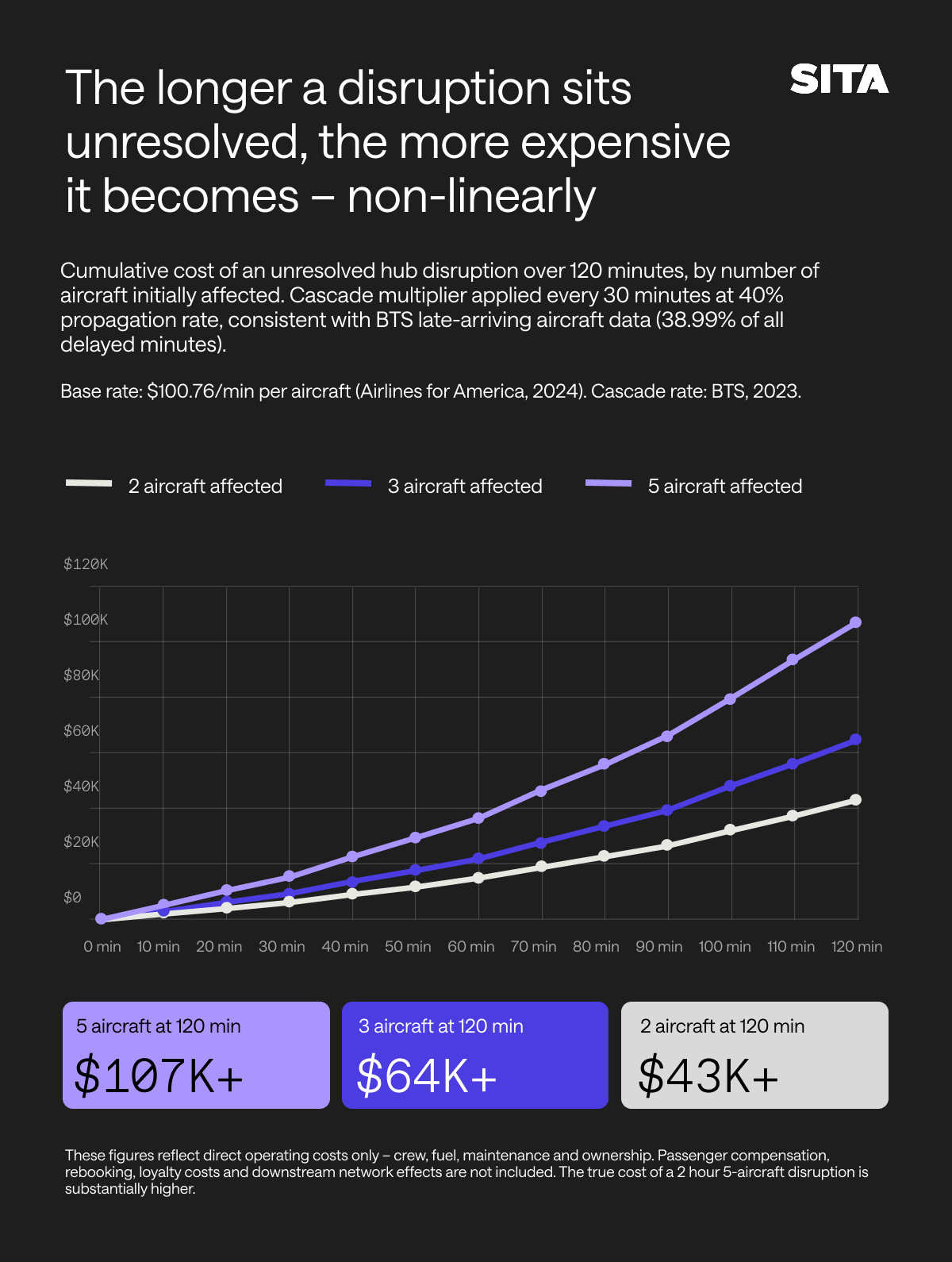
What the industry has been neglecting to measure is the decision window: the narrow interval between the moment a disruption begins, and the moment its downstream consequences become irreversible. It is essential for the Operations Control Center (OCC) to quickly reschedule airline resources to bring disrupted operations back to normal within a short recovery time window. That window is tighter than most people assume. Controllers at hub level typically have minutes to act, not hours, because left unaddressed, a single disruption quickly compounds into a network-wide cascade.
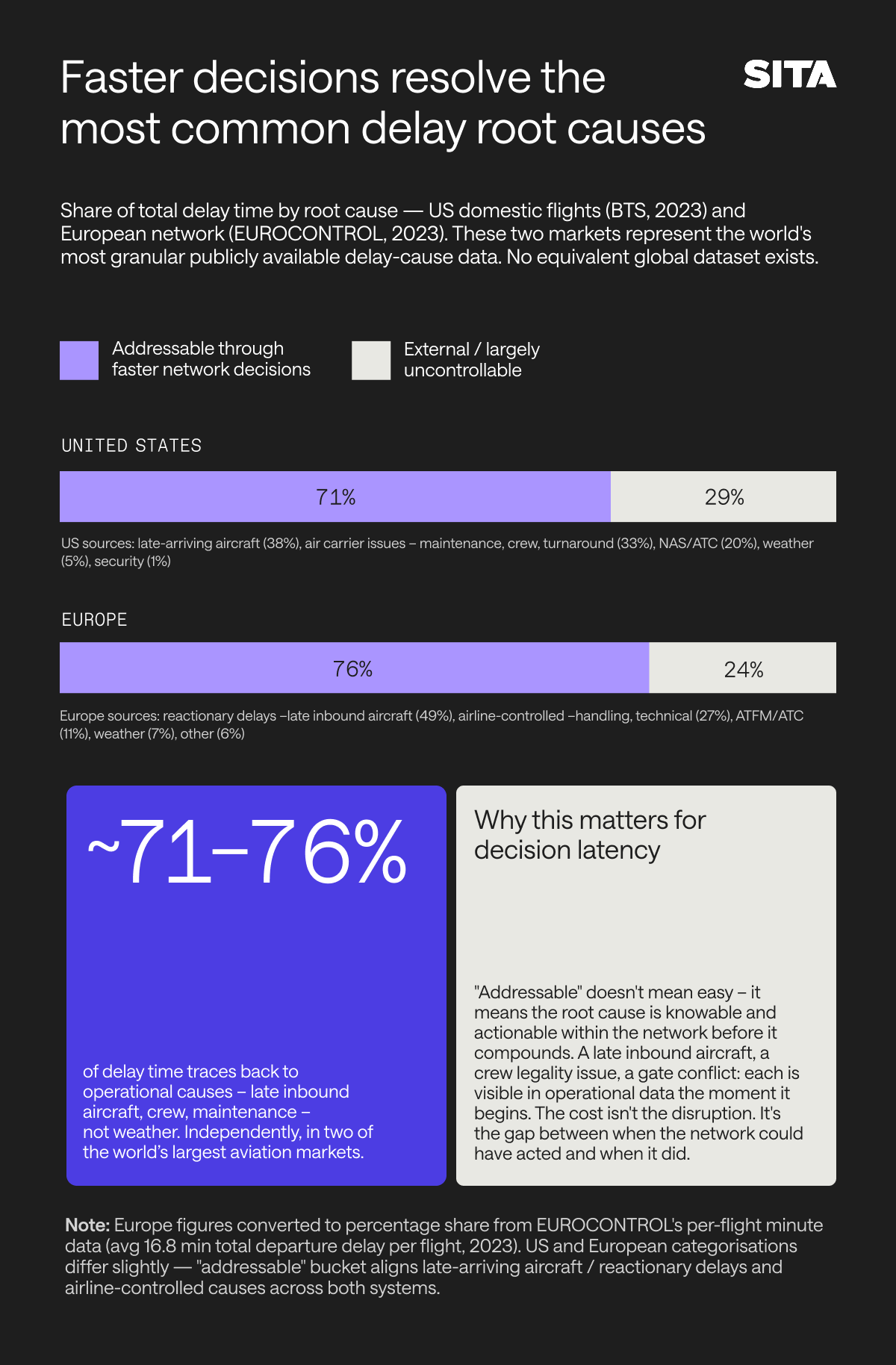
Aviation does not just have a delay problem. It has a decision latency problem. The disruption is the trigger. The cascade is the cost. And the cascade is driven entirely by the gap between when a problem becomes knowable and when the network acts on it as a whole.
A gate agent optimizing their on-time departure metric makes a locally rational call. A ground handler honoring their turnaround SLA does the same. A crew scheduler resolves a legality violation in isolation. Such events create cascading delays and cancellations across the tightly interconnected network. Stack ten of these locally rational decisions on top of each other across a hub in a thunderstorm, and a two-minute slip at 06:00 becomes a four-hour crisis by noon, not because anything went especially wrong, but because nothing was optimized for the whole network.
The misdiagnosis that has cost the industry decades
The standard response to disruption has been to invest in better visibility: improved weather feeds, enhanced crew scheduling software, upgraded dashboards in the OCC. These investments are a great start, but they are not enough. For example, a weather tool might flag a risk early, but if crew, ground, and gates each act separately, the window to recover is still lost.
The decision-making process in airline OCCs is distributed and decentralized across multiple functions, where experts from each function rely on a set of strategies to deploy solutions to dynamic scenarios. The problem is that the architecture forces each of them to optimize their own domain and fragmented, step-by-step decision making overlooks interdependencies among aircraft, crews, maintenance, and airport capacity.
The industry doesn't just need smarter dashboards. It needs technology that can provide a holistic approach to disruption; a single computational layer that replaces local optimization with network optimization in real time.
Three stages. One destination.
The journey to reducing the decision window and making the best network-wide decisions has three stages. Most carriers are between stages one and two. The greatest financial opportunity is found in stage three.
- Stage one: reactive. Human controllers manually cross-reference fleet availability, crew legality, and passenger connections across systems that were never designed to talk to each other. The decision that gets made is rarely optimal; under time pressure, feasible and optimal are not the same thing.
- Stage two: predictive. The best time to manage a disruption is before it happens. By consolidating and correlating real-time data, operations teams gain forward visibility into at-risk flights before impacts happen. Already running in live production environments, ML engines are identifying disruption risk the moment conditions start to turn. They see the storm developing and act before the first snowflake falls.
- Stage three: agentic. This is where the architecture changes entirely. A true agentic network can rebook the passenger, adjust gate assignments, reroute baggage, notify catering, and issue loyalty compensation simultaneously, across every stakeholder. The financial case is already validated in production: internal modeling projects approximately $40K in savings per aircraft, roughly 25% of delay-related costs, equating $6 million annually for a mid-size carrier operating 150 aircraft. In stage one, by the time a controller has assembled a complete picture, the optimal recovery window has already closed. In stage three, it never closes. Always with a human-in-the-loop approach, this isn't about replacing; it's about speeding up and making the most optimal collective decision.

The harder version of the data problem
There is a dimension of this challenge that rarely gets named directly: many of the data silos are intentional. Historically, operational data such as turnaround telemetry, load factors, and crew positioning have been seen as competitive intelligence.
The result is an ecosystem where everyone flies partially blind by design, and where the friction of sharing data has always felt like a greater risk than the friction of not sharing it. By doing so, the decision usually happens after the optimal time needed to avoid the cascade effect.
What network-level AI changes is the economics of that calculus. When a unified operational platform can demonstrate, in your own delay data, that shared data produces measurably better recovery outcomes, the conversation stops being "should we share?" and becomes "what is the minimum viable data contract that unlocks the optimization?" That is a governance question, not a technology question. The technology is ready. The organizational will is where the implementation risk lives.
What leaders need to do differently
Disruption costs won’t decrease with just better tools. It requires a completely different architecture. Three priorities define the path:
- Measure the decision window, not just the delay. The metric that matters is not how long a flight was delayed. It is how long the network took to act after the disruption began. That window is the constraint.
- Invest in local optimization that scale into network solutions. Better scheduling for one department, improved prediction for one hub will continue to underperform as long as the underlying system optimizes only stakeholder by stakeholder. Take as an example, an airline's new OCC feature flags a crew legality risk and swaps the crew. Flight saved. But the ground handler never sees the change, they've already reallocated the turnaround team. A gate conflict surfaces 20 minutes before push-back. The recovery window is gone. The new feature worked perfectly. The network still lost.
- Distinguish agentic from agentic-in-name-only. The market is full of tools that predict disruptions and present options to a human for a decision. True agentic AI can improve your singular operations while also work towards an agentic to agentic (A2A) network which can rebook, reroute, and reallocate to reduce the decision window. The industry has been watching the wrong clock.
The disruption is not what we thought it was and the decision latency is what we need to solve. The carriers who understand that distinction, and act on it, will not just recover faster. They will operate in a fundamentally different category from those who do not.
Next in this series: from theory to the tarmac — how agentic AI is already being deployed in live operational environments, and what the early results tell us.